
WEELメディア事業部LLMライターのゆうやです。
2024年5月15日、Googleから新しいビジョン言語モデル(VLM)の「PaliGemma」が公開されました!
このモデルは、GoogleのVLMであるPaLI-3から着想を得ており、SigLIP-So400mを画像エンコーダとして、Gemma-2Bをテキストエンコーダ統合した、軽量で汎用性の高いVLMです。
最大の特徴は、画像とテキスト両方の入力を理解できるマルチモーダル機能を備えていることで、幅広いタスクに対応できます。
例えば、入力画像を認識して、画像の説明文を出力する「画像キャプション生成」、画像に基づいた質問に対して、適切な回答を生成する「視覚質問応答(VQA)」などのタスクを行えます。
今回は、PaliGemmaの概要と使ってみた感想をお伝えします。
是非最後までご覧ください!
なお弊社では、生成AIツール開発についての無料相談を承っています。こちらからお気軽にご相談ください。


PaliGemmaの概要
PaliGemmaは、Googleが開発したビジョン言語モデルで、画像とテキスト両方の入力を理解できるマルチモーダル機能を備えています。
主要な構成要素は、画像エンコーダー「SigLIP」とテキストデコーダー「Gemma-2B」で、Googleが以前開発したPaLI-3から着想を得ています。
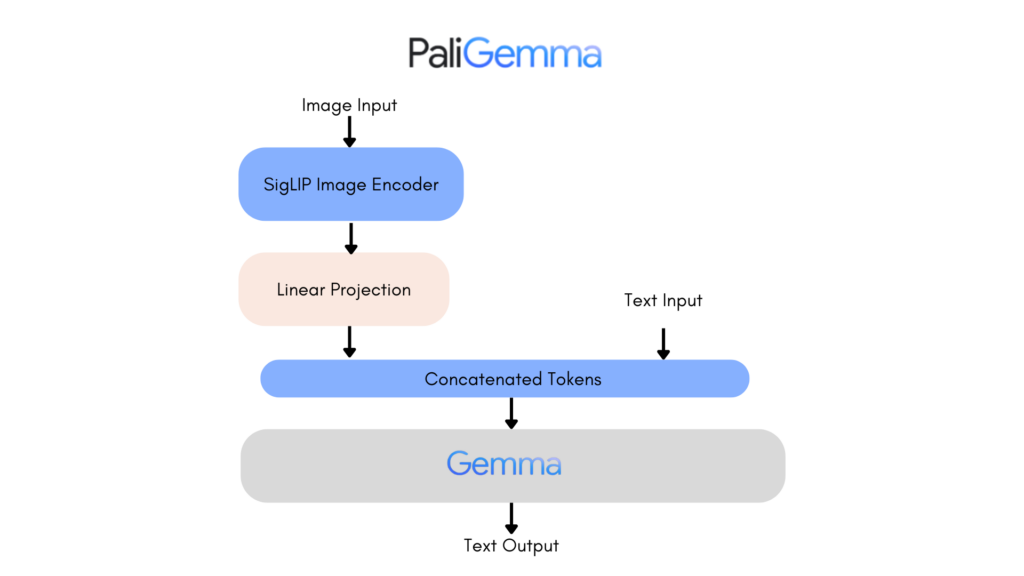
多様なタスクに対応し、画像キャプション生成、視覚質問応答、物体検出、セグメンテーション、文書理解などが可能です。
対応しているタスクの具体的な内容です。
- 画像キャプション生成:
- 画像の内容を自然言語で説明するキャプションを生成します。
- 視覚質問応答(VQA):
- 画像に基づいた質問に対して、適切な回答を生成します。
- 物体検出:
- 画像内の物体を特定し、それらを識別します。
- セグメンテーション:
- 画像内の特定の領域を識別し、セグメント化します。
- 文書理解:
- 画像内のテキストを認識し、その内容を理解します。
また、PaliGemmaは以下の3種類のモデルタイプが公開されています。
- PTモデル: 事前学習済みモデル
- Mixモデル: 複数タスクに対応
- FTモデル: 特定タスクに特化
このモデルは、以下のような画期的な学習プロセスにより視覚と言語の統合能力を高めており、多様なタスクに活用できるようになっています。
- 事前学習(PTモデル):
- 大規模な画像とテキストのペアを使用し、コントラスト学習によって視覚と言語の統合モデルを構築。
- SigLIP-So400mを画像エンコーダー、Gemma-2Bをテキストデコーダーとして使用。
- マルチタスク学習(Mixモデル):
- 複数のタスクに対応するように微調整。
- 一般的な推論に適しており、自由なテキストプロンプトに対応。
- タスク特化型ファインチューニング(FTモデル):
- 特定の学術ベンチマークに最適化。
- 各タスクに対して専用の微調整を実施。
ここからは、PaliGemmaの使い方を解説し、実際に使用してみます。
なお、Googleの表情を自由に編集できるGoogleのアバター生成AIであるVLOGGERについて知りたい方はこちらの記事をご覧ください。

PaliGemmaのライセンス
PaliGemmaは、Google独自のGemma利用規約のもとで提供されており、配布や商用利用も可能になっています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 | |
| 配布 | |
| 特許使用 | – |
| 私的使用 | |

PaliGemmaの使い方
PaliGemmaの使用方法はいくつかありますが、ここではTransformersを使用した方法と、オンラインデモの使い方を解説します。
Transformersの使用
まずは、以下のコードを実行してモデルのロードを行います。
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)次に、以下のコードを実行して入力の前処理と推論を実行します。
prompt = "What is on the flower?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])これで完了です。
また、以下のように4ビットまたは8ビットでモデルをロードすることもできます。
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = PaligemmaForConditionalGeneration.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map={"":0}
)次にオンラインデモを使用する方法を紹介します。
オンラインデモの使用
PaliGemmaは、HuggingFace SpaceでMixモデルのデモが公開されており、以下のリンクから利用できます。
それでは実際に使っていきましょう!
PaliGemmaを実際に使ってみた
まずは画像のキャプションを生成させてみましょう。
以下の画像とプロンプトを入力します。
プロンプト
Caption画像

結果は5秒ほどで以下のキャプションを出力してくれました。
A fluffy gray and white cat sits peacefully in the grass, its eyes wide open. The cat's fur is soft and silky, and its eyes are bright and full of life. The flowers in the garden bloom in a variety of colors, including pink, white, and red. The cat's ears are perked up, and its tail is swiped across the grass. The cat's eyes are full of wonder, and its nose is wrinkled in concentration.ふわふわの灰色と白の猫が草むらに安らかに座っています。猫の毛は柔らかく絹のようで、その目は明るく生命力に溢れています。庭にはピンク、白、赤などさまざまな色の花が咲いています。猫の耳はピンと立ち、尻尾は草の上をスーッと横切ります。猫の目は驚きに満ち、鼻にしわを寄せて集中しています。
おおよそ正しく描写できていると思いますが、画像には写っていないしっぽに関する説明があり完全に正しいものとは言えません。
次は、VQAを試してみます。
以下の画像とプロンプトを入力します。
プロンプト
In which city is this?これはどこの都市ですか?
画像

結果はこのように正しく東京だと認識して回答してくれました。
tokyo東京
次に、同じ東京の画像を利用して物体検出をしてみます。
以下のプロンプトを入力します。
detect towerタワーを検出して
結果はこのようになりました。
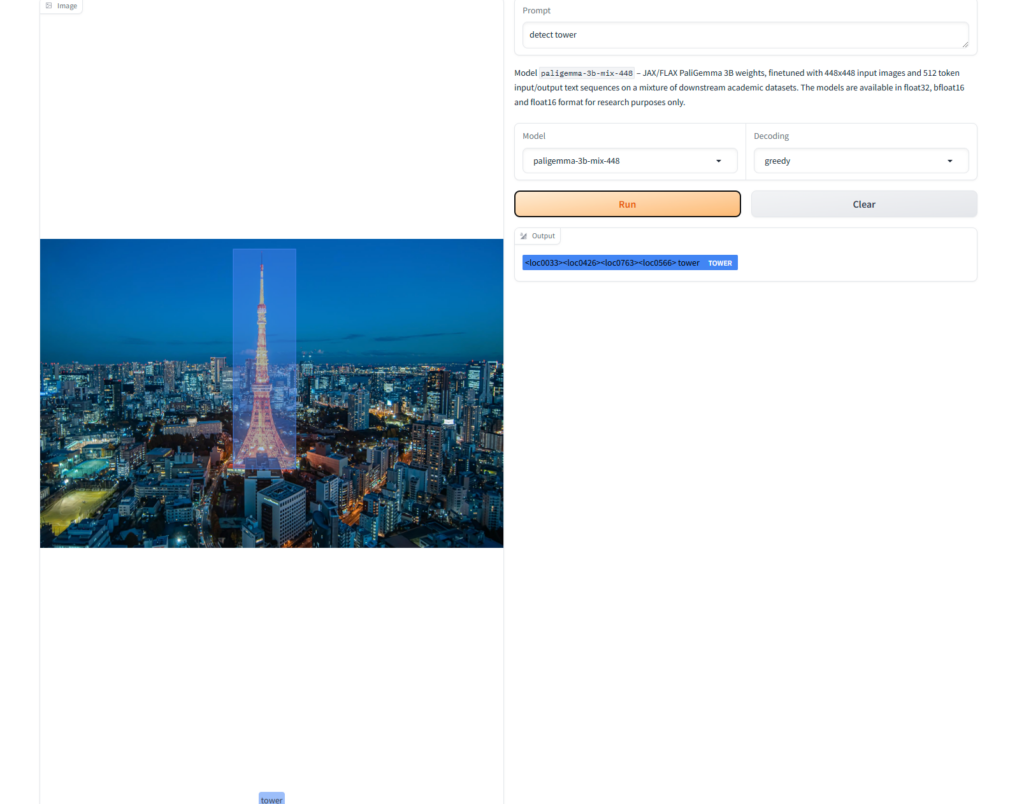
画像から正しくタワーを検出できています。
最後に、画像の文章の理解を試してみます。
以下の画像とプロンプトを入力します。
プロンプト
What does this image show?画像
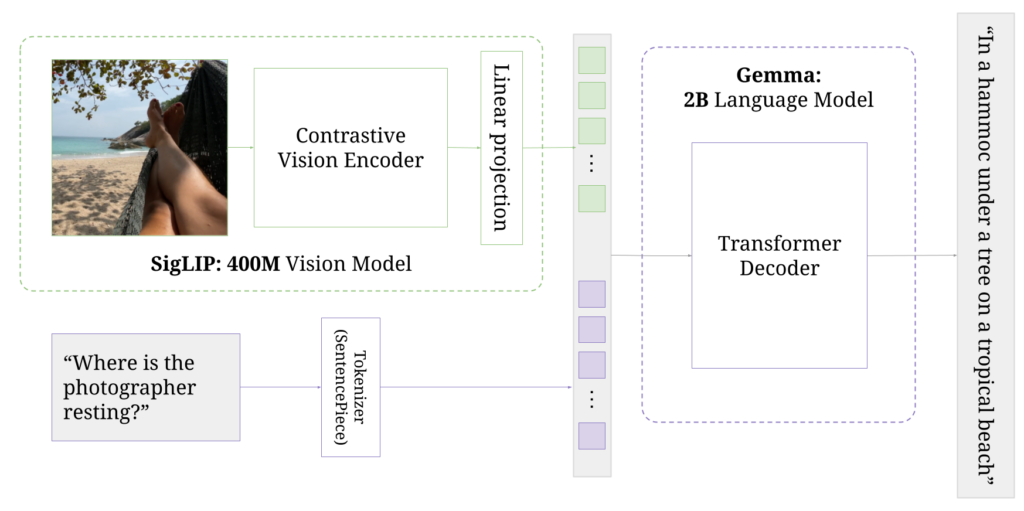
結果はこのようになりました。
our model pipeline.私たちのモデルパイプライン。
この画像がPaliGemmaのモデル概要図であることを文章などから認識したうえで、私たちのモデルパイプラインであると答えています。
実際に使ってみたところ、かなり高い画像認識能力を持っていることが伺えます。
PaliGemmaの実行に必要なスペック
PaliGemmaの実行には、かなり高い性能のGPU(A100やA10Gなど)が必要になります。
また、RAMも32GB以上必要になるとのことです。
ここからは、PaliGemmaの性能をさらに検証するため、画像認識能力を最近(2024年5月)公開されたばかりのGPT-4oと比較していきます。
PaliGemmaの画像認識能力をGPT-4oと比較してみた
2~3日以内に、更新します!
ブックマークをしてお待ちください。
なお、GPT-4oについて知りたい方はこちらの記事をご覧ください。

PaliGemmaは高い性能を持った次世代オープンソースVLM
PaliGemmaはGoogleが開発した視覚と言語の統合モデル(VLM)で、画像とテキストを統合して処理し、多様なタスクに対応します。
対応するタスクには画像キャプション生成、視覚質問応答(VQA)、物体検出、セグメンテーション、文書理解があります。
主な構成要素は画像エンコーダー「SigLIP-So400m」とテキストデコーダー「Gemma-2B」で、事前学習済みモデル(PT)、複数タスク対応モデル(Mix)、特定タスク特化型モデル(FT)の3種類があります。
実際に使ってみたところ、かなり高い精度で画像を理解して回答を出力してくれました。
今後は、大規模言語モデル(LLM)の「Gemma 2」のリリースも予定されており、今後のGemmaシリーズの動向に目が離せません!

生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIのコンサルティング
・システム間API連携
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
 ︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。



















